读文件时内部工作机制参看下图:
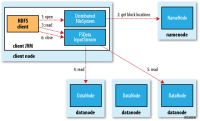
客户端通过调用FileSystem对象(对应于HDFS文件系统,调用DistributedFileSystem对象)的open()方法来打开文件(也即图中的第一步),DistributedFileSystem通过RPC(Remote Procedure Call)调用询问NameNode来得到此文件最开始几个block的文件位置(第二步)。对每一个block来说,namenode返回拥有此block备份的所有namenode的地址信息(按集群的拓扑网络中与客户端距离的远近排序,关于在Hadoop集群中如何进行网络拓扑请看下面介绍)。如果客户端本身就是一个datanode(如客户端是一个mapreduce任务)并且此datanode本身就有所需文件block的话,客户端便从本地读取文件。
以上步骤完成后,DistributedFileSystem会返回一个FSDataInputStream(支持文件seek),客户端可以从FSDataInputStream中读取数据。FSDataInputStream包装了一个DFSInputSteam类,用来处理namenode和datanode的I/O操作。
客户端然后执行read()方法(第三步),DFSInputStream(已经存储了欲读取文件的开始几个block的位置信息)连接到第一个datanode(也即最近的datanode)来获取数据。通过重复调用read()方法(第四、第五步),文件内的数据就被流式的送到了客户端。当读到该block的末尾时,DFSInputStream就会关闭指向该block的流,转而找到下一个block的位置信息然后重复调用read()方法继续对该block的流式读取。这些过程对于用户来说都是透明的,在用户看来这就是不间断的流式读取整个文件。
当真个文件读取完毕时,客户端调用FSDataInputSteam中的close()方法关闭文件输入流(第六步)。
如果在读某个block是DFSInputStream检测到错误,DFSInputSteam就会连接下一个datanode以获取此block的其他备份,同时他会记录下以前检测到的坏掉的datanode以免以后再无用的重复读取该datanode。DFSInputSteam也会检查从datanode读取来的数据的校验和,如果发现有数据损坏,它会把坏掉的block报告给namenode同时重新读取其他datanode上的其他block备份。
这种设计模式的一个好处是,文件读取是遍布这个集群的datanode的,namenode只是提供文件block的位置信息,这些信息所需的带宽是很少的,这样便有效的避免了单点瓶颈问题从而可以更大的扩充集群的规模。
|
Hadoop中的网络拓扑 在Hadoop集群中如何衡量两个节点的远近呢?要知道,在高速处理数据时,数据处理速率的唯一限制因素就是数据在不同节点间的传输速度:这是由带宽的可怕匮乏引起的。所以我们把带宽作为衡量两个节点距离大小的标准。
|
现在我们来看一下Hadoop中的写文件机制解析,通过写文件机制我们可以更好的了解一下Hadoop中的一致性模型。
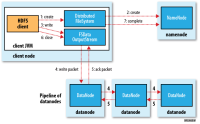
上图为我们展示了一个创建一个新文件并向其中写数据的例子。
首先客户端通过DistributedFileSystem上的create()方法指明一个欲创建的文件的文件名(第一步),DistributedFileSystem再通过RPC调用向NameNode申请创建一个新文件(第二步,这时该文件还没有分配相应的block)。namenode检查是否有同名文件存在以及用户是否有相应的创建权限,如果检查通过,namenode会为该文件创建一个新的记录,否则的话文件创建失败,客户端得到一个IOException异常。DistributedFileSystem返回一个FSDataOutputStream以供客户端写入数据,与FSDataInputStream类似,FSDataOutputStream封装了一个DFSOutputStream用于处理namenode与datanode之间的通信。
当客户端开始写数据时(第三步),DFSOutputStream把写入的数据分成包(packet), 放入一个中间队列——数据队列(data queue)中去。DataStreamer从数据队列中取数据,同时向namenode申请一个新的block来存放它已经取得的数据。namenode选择一系列合适的datanode(个数由文件的replica数决定)构成一个管道线(pipeline),这里我们假设replica为3,所以管道线中就有三个datanode。DataSteamer把数据流式的写入到管道线中的第一个datanode中(第四步),第一个datanode再把接收到的数据转到第二个datanode中(第四步),以此类推。
DFSOutputStream同时也维护着另一个中间队列——确认队列(ack queue),确认队列中的包只有在得到管道线中所有的datanode的确认以后才会被移出确认队列(第五步)。
如果某个datanode在写数据的时候当掉了,下面这些对用户透明的步骤会被执行:
1)管道线关闭,所有确认队列上的数据会被挪到数据队列的首部重新发送,这样可以确保管道线中当掉的datanode下流的datanode不会因为当掉的datanode而丢失数据包。
2)在还在正常运行的datanode上的当前block上做一个标志,这样当当掉的datanode重新启动以后namenode就会知道该datanode上哪个block是刚才当机时残留下的局部损坏block,从而可以把它删掉。
3)已经当掉的datanode从管道线中被移除,未写完的block的其他数据继续被写入到其他两个还在正常运行的datanode中去,namenode知道这个block还处在under-replicated状态(也即备份数不足的状态)下,然后他会安排一个新的replica从而达到要求的备份数,后续的block写入方法同前面正常时候一样。
有可能管道线中的多个datanode当掉(虽然不太经常发生),但只要dfs.replication.min(默认为1)个replica被创建,我们就认为该创建成功了。剩余的replica会在以后异步创建以达到指定的replica数。
当客户端完成写数据后,它会调用close()方法(第六步)。这个操作会冲洗(flush)所有剩下的package到pipeline中,等待这些package确认成功,然后通知namenode写入文件成功(第七步)。这时候namenode就知道该文件由哪些block组成(因为DataStreamer向namenode请求分配新block,namenode当然会知道它分配过哪些blcok给给定文件),它会等待最少的replica数被创建,然后成功返回。
|
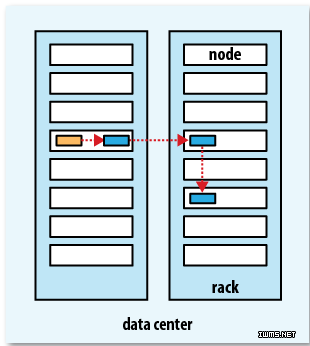
replica是如何分布的 Hadoop在创建新文件时是如何选择block的位置的呢,综合来说,要考虑以下因素:带宽(包括写带宽和读带宽)和数据安全性。如果我们把三个备份全部放在一个datanode上,虽然可以避免了写带宽的消耗,但几乎没有提供数据冗余带来的安全性,因为如果这个datanode当机,那么这个文件的所有数据就全部丢失了。另一个极端情况是,如果把三个冗余备份全部放在不同的机架,甚至数据中心里面,虽然这样数据会安全,但写数据会消耗很多的带宽。Hadoop 0.17.0给我们提供了一个默认replica分配策略(Hadoop 1.X以后允许replica策略是可插拔的,也就是你可以自己制定自己需要的replica分配策略)。replica的默认分配策略是把第一个备份放在与客户端相同的datanode上(如果客户端在集群外运行,就随机选取一个datanode来存放第一个replica),第二个replica放在与第一个replica不同机架的一个随机datanode上,第三个replica放在与第二个replica相同机架的随机datanode上。如果replica数大于三,则随后的replica在集群中随机存放,Hadoop会尽量避免过多的replica存放在同一个机架上。选取replica的放置位置后,管道线的网络拓扑结构如下所示:
|
HDFS某些地方为了性能可能会不符合POSIX(是的,你没有看错,POSIX不仅仅只适用于linux/unix,Hadoop 使用了POSIX的设计来实现对文件系统文件流的读取),所以它看起来可能与你所期望的不同,要注意。
创建了一个文件以后,它是可以在命名空间(namespace)中可以看到的:
Path p = new Path("p");
fs.create(p);
assertThat(fs.exists(p), is(true));
但是任何向此文件中写入的数据并不能保证是可见的,即使你flush了已经写入的数据,此文件的长度可能仍然为零:
Path p = new Path("p");
OutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.flush();
assertThat(fs.getFileStatus(p).getLen(), is(0L));
这是因为,在Hadoop中,只有满一个block数据量的数据被写入文件后,此文件中的内容才是可见的(即这些数据会被写入到硬盘中去),所以当前正在写的block中的内容总是不可见的。
Hadoop提供了一种强制使buffer中的内容冲洗到datanode的方法,那就是FSDataOutputStream的sync()方法。调用了sync()方法后,Hadoop保证所有已经被写入的数据都被冲洗到了管道线中的datanode中,并且对所有读者都可见了:
Path p = new Path("p");
FSDataOutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.flush();
out.sync();
assertThat(fs.getFileStatus(p).getLen(), is(((long) "content".length())));
这个方法就像POSIX中的fsync系统调用(它冲洗给定文件描述符中的所有缓冲数据到磁盘中)。例如,使用java API写一个本地文件,我们可以保证在调用flush()和同步化后可以看到已写入的内容:
FileOutputStream out = new FileOutputStream(localFile);
out.write("content".getBytes("UTF-8"));
out.flush(); // flush to operating system
out.getFD().sync(); // sync to disk(getFD()返回与该流所对应的文件描述符)
assertThat(localFile.length(), is(((long) "content".length())));
在HDFS中关闭一个流隐式的调用了sync()方法:
Path p = new Path("p");
OutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.close();
assertThat(fs.getFileStatus(p).getLen(), is(((long) "content".length())));
由于Hadoop中的一致性模型限制,如果我们不调用sync()方法的话,我们很可能会丢失多大一个block的数据。这是难以接受的,所以我们应该使用sync()方法来确保数据已经写入磁盘。但频繁调用sync()方法也是不好的,因为会造成很多额外开销。我们可以再写入一定量数据后调用sync()方法一次,至于这个具体的数据量大小就要根据你的应用程序而定了,在不影响你的应用程序的性能的情况下,这个数据量应越大越好。
转载请注明出处:http://www.cnblogs.com/beanmoon/archive/2012/12/17/2821548.html
猜您喜欢:
1.使用Linux和Hadoop进行分布式计算
2.Hadoop架构设计、运行原理详解
3.Hadoop 2.3.0解决了哪些问题
Hadoop故障排除:jps 报process information unavailable解决办法,jps时出现如下信息:4791 -- process information unavailable
解决方法could only be replicated to 0 nodes, instead of 1,1、停止hadoop脚本:bin/stop-all.sh(在进行2、3步前,注意数据的备份)2、删除主节点和从节点上的hadoop根目录下的临时文件夹,比如$HADOOP_HOME/hadooptmp。
hbase是什么? 首先hbase是一个在Hadoop的HDFS分布,hbase集群中的节点分为HMaster Server和HRegion Server两种,采用Master-Slave的模式,但是不像hadoop中的集群那样有单点故障的问题。
Hypertable on HDFS(hadoop) 安装,安装指南过程4.2.Hypertable on HDFS创建工作目录$ hadoop fs -mkdir /hypertable$ hadoop fs -chmod 777 。
大约十年前,业界开始采用 Reed Solomon code对数据分发两份或三份,替代传统的RAID5或RAID6。由于采用了廉价的磁盘替代昂贵的存储阵列,所以这种方法非常经济。Reed Solomon code和XOR都是Erasure Code的分支。其中,XOR只允许丢失一块数据,而Reed Solomon code可以容
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。